Over time, one accumulates a set of knowledge that can help them to understand and to debug various types of software problems.
The following is a quick braindump of some things that I’ve learned while working with SQL Server over the last few years. This post is not comprehensive, it’s probably wrong in many respects. I look to you, dear Internet, to correct me.
###Platinum Rule:
Everything I know is wrong (for some cases, and some definitions of ‘wrong’). “Rules” listed here are heuristic, and exceptions exist more frequently than not.
###Golden Rule:
It’s all about Balance.
SQL is bound by the rules of the Von Neumann architecture, just like (probably) every other computer you’ve ever used. This means that there is a constant contention for memory and processing resources. The SQL Engine is black magic. But, it’s not totally unpredictable; The decisions it makes are directly in response to the fundamental resource contention that exists on all computers.
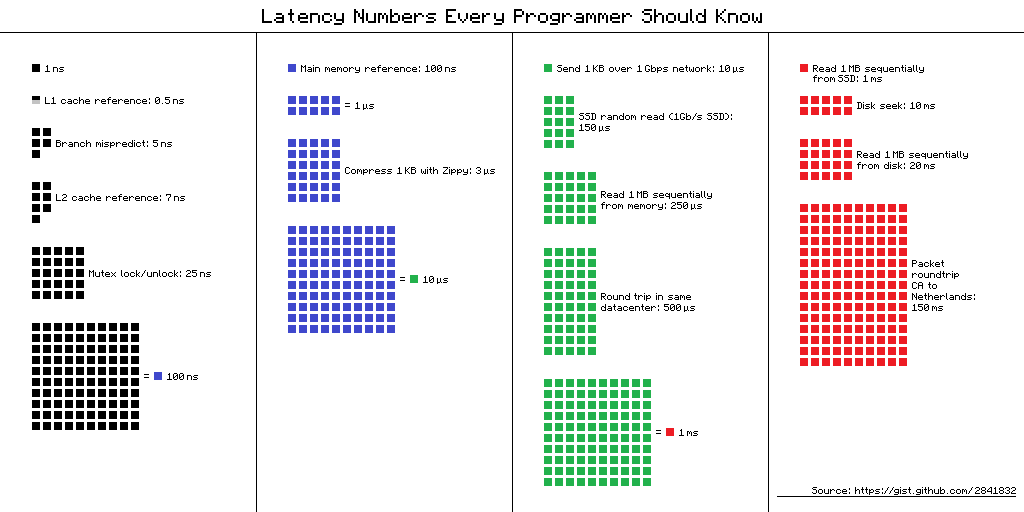
By far, the largest performance bottleneck for most applications is the time that is required to do reads/writes to disk and transfer of data over the wire. Therefore, minimizing reads/writes, and tuning what types of reads/writes are done (sequential vs. random) are typically the two best investments of time for tuning SQL.
The following is a diagram of the relative performance of various IO operations. Understanding where in the IO pipeline you’re willing to make tradeoffs is the first step to optimizing your use of SQL Server.
###Silver Rule:
SQL servers are typically general purpose. The database is optimized for the “average” use case (though, it does dynamically tune itself). Therefore, sometimes the best answer is to bring a slightly larger dataset back from the server and to do the calculations in application code (on app servers that can be scaled horizontally, more easily).
###Hints:
- Table-scans mean the server is doing many reads against the disk.
- Table-scans typically indicate that an appropriate index does exist, or is not being leveraged.
- It’s really important to account for how large the table in question is. (i.e., it is generally not productive to optimize a 10MB table)
- Understanding locking is pretty important:
- Microsoft’s article
- Locks come in several sizes, “row” to “database”
- Locks can be non-exclusive, or exclusive (read vs. read/write)
- Locks cause waits.
- Joins cause locks.
- Writes cause locks.
- Locks block writes (and sometimes reads).
- Aggregate queries (
sum,average,count, etc.) can cause locks/table-scans. - Full-text queries are generally expensive (especially “contains”-type queries:
LIKE = '%string%') - “CONTAINS” queries can be expensive, because they often result in non-optimal use of indexes
- Variable numbers of elements in a “
CONTAINS(@p0, @p1)“-type clause result in different SQL execution plans, compilation of which is a large cost of many queries. - SQL will cache the top X execution plans, this is variable, and dependent upon memory constraints.
- Clustered indexes cause the data to be written in a specific order on disk, this allows SQL to make intelligent choices about table-scans vs. index-seeks. Therefore, ALL tables should have a clustered index, and this should generally be a monotonically increasing (or decreasing) value (such as an int).
- Estimating table-size
- Estimating table size
- SQL Data types
- Integer sizes
- varchar/nvarchar: varchar uses 1-byte chars (ASCII-extended encoding), nvarchar uses 2-byte chars (UCS-2 encoding).
- [N]VARCHAR(MAX) uses a variable amount of space, and requires more “logical reads” when accessed, due to the way that it is organized on disk (not co-located with the rest of the table data).
- Indexes are B-Trees
- Microsoft info on indexes
- Generally, inclusion of columns in an index should be ordered “general to specific.” This allows nodes to be partitioned in a progressively more specific levels.
- Unless there is a use case where data in the table will be accessed by a highly specific value (ID, for example). Then there may be the need for an index that has that as the first column, maybe.
- N+1 queries are bad because they result in many round-trips to the server, and many logical reads by the server, both of these activities are VERY SLOW compared to processor time.
- For most applications, “in data-center bandwidth” is plentiful.
- Therefore, somewhat larger result sets over the wire are preferred to hammering a resource-constrained SQL server.
- Generally, writes should be batched when possible. SQL can optimize writes to disk better, when dealing with bulk writes.
- There are many cases where batching bulk writes will be infeasible.
- It is possible to batch too many writes to SQL, escalating locks and expanding the TempDB in such a way that you actually hurt overall performance.
- ACID adds overhead, not everything requires ACID.
- If you don’t need ACID, you can relax some SQL Server constraints, but you might want to use another “Non-SQL” solution, instead.